15-418 · Parallel Computer Architecture
LZ Compression
Jack Woodson (jrwoodso) & Alex Li (alexli3)
Overview
Summary
Will investigate how to parallelize the serial compression algorithms LZ77 and LZW. As we try to parallelize, we would also compare how much performance (compression ratio) we can retain while speeding up the computation. We will target the GHC machine, and extend to the PSC to test scalability on higher core counts.
Background
LZ Compression
LZ-family compression algorithms form the foundation of widely-used formats like ZIP, PNG, and GIF. Both algorithms exploit repetition in data: rather than storing repeated sequences in full, they encode references to prior occurrences, achieving significant size reduction.
There are various different forms of LZ compression and the methods that either benefit speed with low compression ratio, vice versa, or memory consumption. The different LZ compression algorithms that we will be increasing their performance are LZ77 and LZW.
Makes use of a sliding windows technique to process current data with previously processed / compressed data.
Takes in a set of symbols and converts them into a code that takes less file size. These codes and symbols are stored in a dictionary for easy, low cost lookup. If these symbols appear again they are substituted for the short code.
Problem Space
Challenge
These algorithms heavily rely on finding code or symbols that are repeated early on in the compression process to be able to shorten the repetition. When working with multiple threads this task becomes increasingly more difficult as they will either create unique codes for these symbols individually taking up too much memory leading to a poor compression ratio, or waiting for threads to load to memory creating specific bottlenecks.
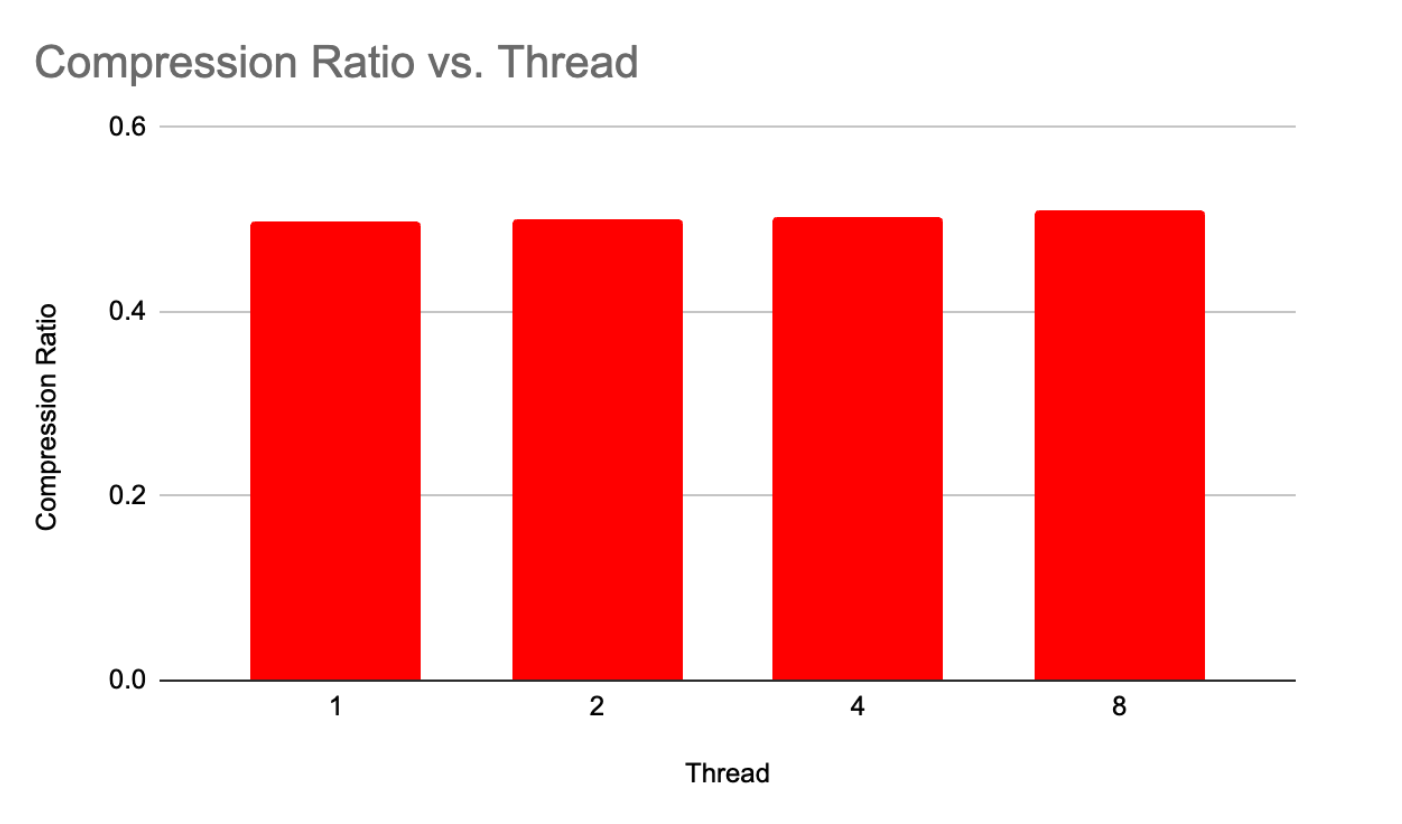
Our project will tread this fine line to be able to optimize our code working with multiple threads while maintaining a good compression ratio.
- Memory access characteristics
- Communication to computation issues
- Divergent execution and load balancing
- Compression ratio performance constraints
Deliverables
Goals and Deliverables
- Working sequential LZ77 and LZW with competitive compression ratios on standard benchmarks
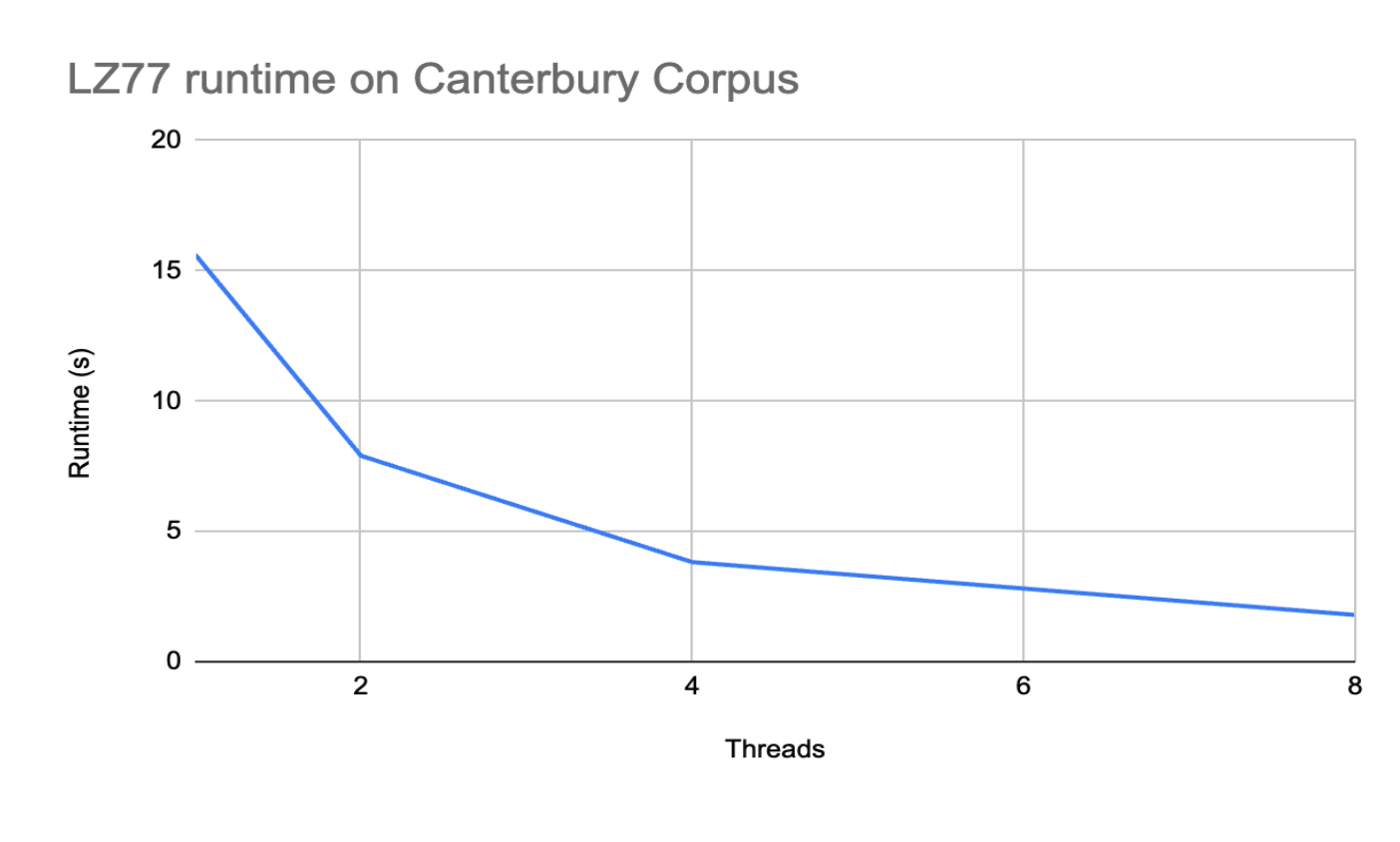
- Parallel LZ77 with at least 4–6× speedup on 8 GHC cores
- Less than 15% degradation in compression ratio
- Extend to LZW and begin PSC scaling exploration
- Analysis of what limits scaling (memory, synchronization, load imbalance)
- The project is already quite aggressive; it almost already encompasses what we hope to achieve
- Alternative pre-initialization strategies
- Speculative approaches to further improve speed and performance
- Focus only on LZ77 if work is significantly harder to implement or parallelize
- Refine parallel LZ77 implementation
- Deeper analysis on LZ77 with surface-level observations on LZW
Infrastructure
Platform Choice
Our platform choice is going to primarily consist of work done on the GHC machines. This is due to the availability we have as students and able to play around with different thread counts with these compression algorithms. Additionally, as we are trying to create the most parallel efficient algorithms we also plan to make use of the PSC machines to test and see how our algorithm runs with higher thread counts 16–128.
Also, a multicore CPU is also a better fit for this workload than a GPU. LZ compression involves irregular, backward-looking memory accesses (LZ77's sliding window) and dynamic dictionary lookups (LZW) — both of which map poorly to GPU architectures that require coalesced memory access patterns to perform well.
GHC Machines
Up to 8 cores. Primary development platform. Available as students to experiment with different thread counts.
PSC Machines
Up to 128 cores. Used to demonstrate how algorithms scale with significantly more threads and increased computing power.
References
Resources
We plan to write this code from scratch while making use of helpful references. No additional resources beyond GHC and PSC should be needed. We anticipate potential issues with scaling on the PSC that will not be noticed on the GHC machines at 8 cores.
Timeline
Schedule
Apr 4
Working LZ77 and LZW sequential algorithms that yield an optimal compression ratio.
Important to be able to have a good sequential baseline to measure our efforts in increasing speedup.
Additionally create a good test set that comprises files of different information, highly repetitive, no repetition and of different sizes.
Apr 11
Working compression algorithm for LZ77 that are able to achieve relatively high speedup on lower thread counts but are in the right direction in being able to get a good workload balance and scaling at higher thread counts.
As there are similarities between LZ77 and LZW we will primarily focus on LZ77 first as a lot of the ideas for increased performance should translate to the LZW method.
Keep up to date with changes and requirements in milestone for April 14.
Apr 18
Have a LZ77 compression algorithm that has good scalability and good compression ratio with some small improvements.
Keep website up to date with milestone and changes made.
Apr 30
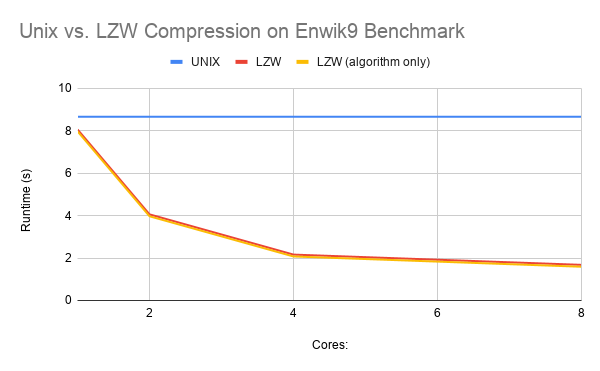
Have a LZW compression algorithm that has good scalability and good compression ratio with some small improvements. Compare these two different algorithms that we've been working to find the best compression algorithm with lower thread counts, to higher, and memory usage.
Additionally, meet all other requirements for website.